
Classification, Localization & Detection
Intro
This is a course on Object Detection. In this, I will be covering some of the important papers in this field like HOG, Overfeat, Faster RCNN etc. A detailed tutorial is available in YouTube. The same topic is covered in brief in this blog.
But before jumping into the topic, lets first understand the differences between Image Classification, Object Localization and Object Detection.
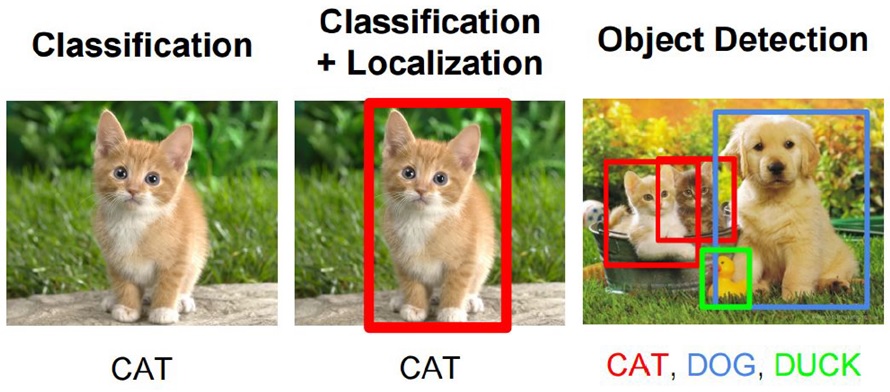
Classification
Given an image with one object, we tell what kind of object it is. This is the case of classification.
Localization
Next comes localization, where we not only tell what kind of object it is, but we also locate it in the image. Programmatically speaking, we have to draw the correct bounding box around it, like the red box in the above figure.
Object Detection
If there are more than one objects in the image, we have to locate and identify all of them. This task is Object Detection.
Ideas for Localization
In this tutorial, I will be mainly concentrating on Object Detection. But lets first understand Object Localization. This is a task of locating an object in an image. That is, there is a single object in the image and we have to correctly draw the bounding box around it. Now, the question is, how shall we do it? Lets think of some of the approaches.
Note: I am assuming, that, you are already familiar with Image Classification using ConvNets like AlexNet, VGGNet etc.
Since we already know how to do Image Classification, let’s see if we can use the same ConvNet as a base and extend it to do Localization. In classification, the network outputs 1 value per class (Person, Cat, Ball etc).
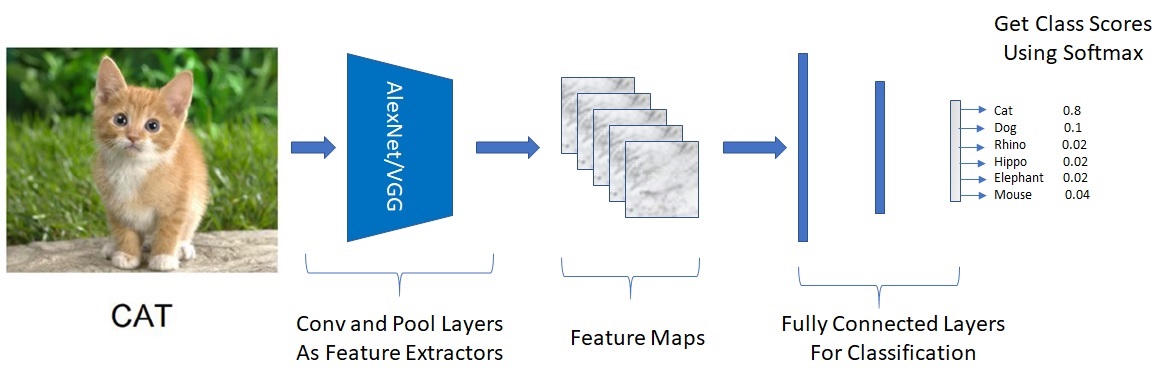
Problem - Need 4 outputs per class
But for Localization, to get the bounding box, we need 4 outputs per class.
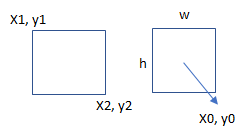
These 4 outputs would correspond to x1,y1,x2,y2 co-ordinates of the bounding box. Or, they can be the mid point of the box (x0, y0) and the height and width (h,w) of the box. Either way, we would be needing 4 values.
So, how shall we do it?
Solution - Modify last layer
In reality, it is not so complicated. We just need to modify the last Fully Connected layer of the network to output 4 values for each class instead of 1. That’s it. Conceptually it is as simple as that.
And since, here we are interested in the absolute values of the co-ordinates and not the probabilities, we would not be needing the Softmax layer at the end.
Also, we need to change the way the loss is calculated. In case of classification, we use log loss, but here we need to use any of the Regression Loss functions like L1 or L2 loss. With these changes, we need to train the network to output correct values for these co-ordinates.
But, this does not mean, that we can throw away the Classification layer. We still need it to know what kind of object it is. So, by combining the results of both Classifier and BBox Regressor, we can infer the type of the object and its location.
This is how the Object Localization Network would look like.
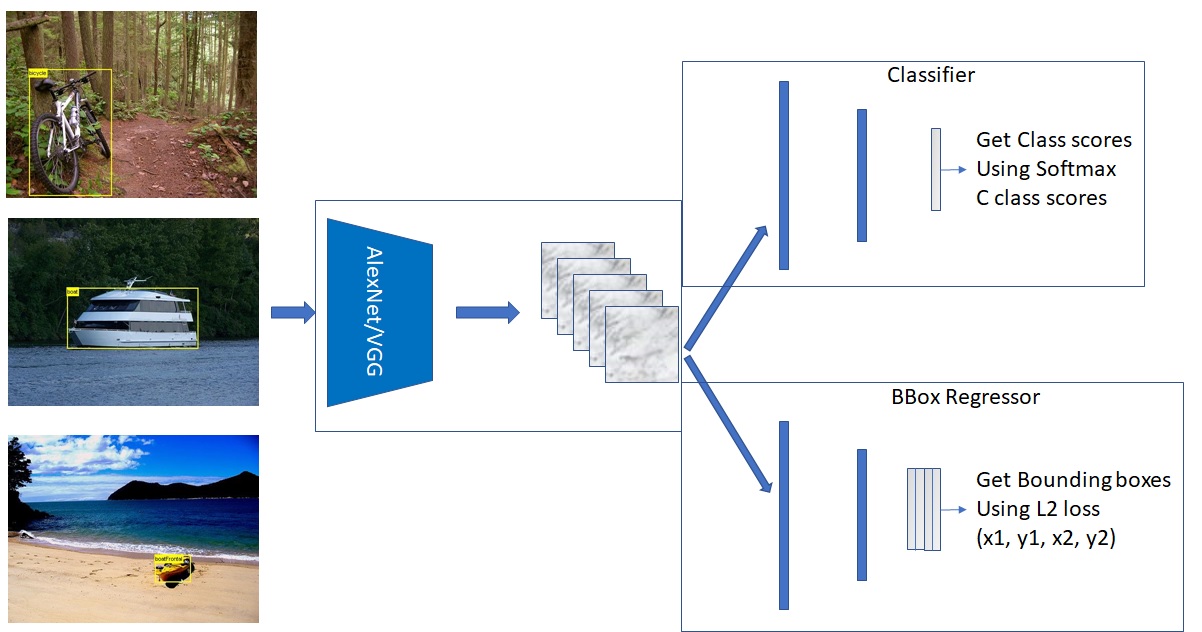
This way, by reusing the same convolution layers and by adding a few FC layers, we are able to do Object Localization.
A detailed discussion is in this video.
Ideas for Object Detection
In the above discussion, we used the Classification ConvNet as the base and extended it to do Localization.
On the same lines, can we extend the Localization network to locate more than one object? If so, how?
Note: The Convolution Networks like AlexNet, VGGNet etc need input images to be of fixed size like 224x224.
Single Object

If there is only one object in an image, there is no problem. We can just resize the image to the required dimension and use the same localization network.
Two Objects
How do we handle the case of 2 objects?

One simple hack would be to just split the image into 2, so that the 2 objects are separated. Now we can resize the images and reuse the same localization network, locate the objects in the 2 separate images. Later, we can just translate the co-ordinates onto the original image.
Problem - Any number of objects

While the above approach would work, this would not be a generic solution. Since there can be any number of objects in the image and neither do I know the number of objects, nor their locations before hand.
So, how can we solve this problem?
Solution - Sliding Window
Since we neither know the number of objects nor their location, the only option left is to scan all possible locations in an image.
To do this, we can take crops at all possible locations in the image and feed it to the localization network.
Then, this network, will take a look at the patch and will decide if there is an object in that patch. If so, it will give us the bounding box (bbox).
This technique is called the ‘Sliding Window’.

So, this way, by reusing the same Localization network, I will be able to do object detection by doing some preprocessing on the image.
What are the preprocessing steps?
- Use Sliding Window and crop the image patches and
- Resize the image to a fixed size (Since the Localization network expects the input to be of a fixed size)
Problem - Objects of Different Sizes
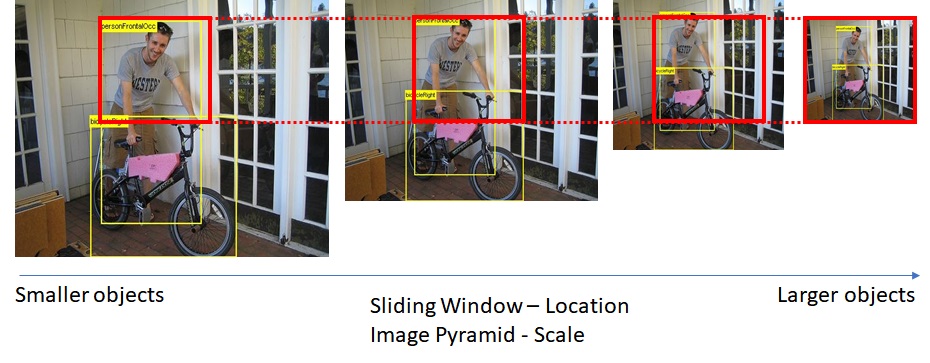
But still there is a problem with this approach. We cant expect objects in the image to be of similar sizes. As you can see in the image below, the sliding window size (red box) is insufficient to cover the person or bycycle completely. So using a fixed size Sliding Window may not solve the problem.

So, what is the solution to this problem?
Solution - Image Pyramid
Either I have to use Sliding windows of different sizes or resize the main image itself, keeping the Sliding Window size constant. Usually the 2nd approach is taken.
Experimentally, it is found that scaling the image to six different sizes would be good enough to locate most of the objects. Smaller objects get detected in Larger scaled image and Larger objects get detected in Small Scaled images. This concept is called Image Pyramid.
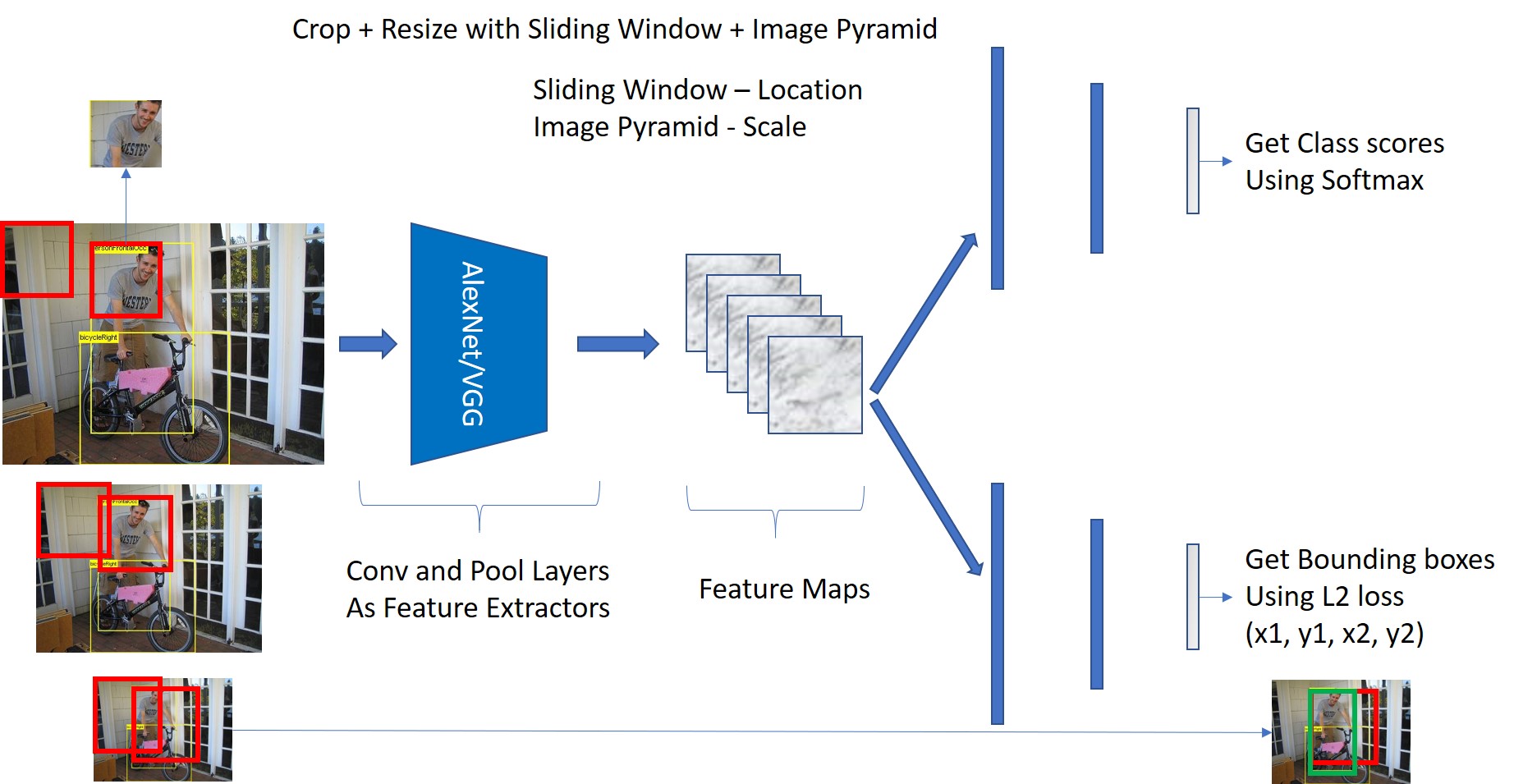
Preprocessing at the input side
So, these are the additional preprocessing I have to do on the input side to do Object Detection. The Sliding Window will take care of the location of the object and Image Pyramid will take care of the Size of the object.
With these changes, I will be able to do Object Detection with the same Localization Network as the base. Only thing that I added were a bit of pre-processing steps.
Problem - Too many inputs
Though we have solved the problem of Detection using Sliding Window and Image Pyramid, along with the Localization Network, this still leads us to another problem.
Since we are cropping image patches at all locations in the image and resizing before giving it as input to the Localization Network, we end up with too many inputs to the network. Just to process 1 single image.
For example, to process an image of 800x800, if the sliding window size is 224, we will end up with 331,776 crops.
Since CNNs are very processing intensive, this will be an expensive operation. So, how do we solve this problem? We will see this in the next section.
A detailed discussion is in this video.